Moving to issues as the new PRs
· 4 min read

In the olden days, contributing your first PR to an open source project was rather involved. Even with great instructions, getting the project to build, the app to run and the tests to pass took real work. And even if you knew exactly which bug to fix, you needed a rough understanding of the project’s architecture and more detailed knowledge of the code you were changing.
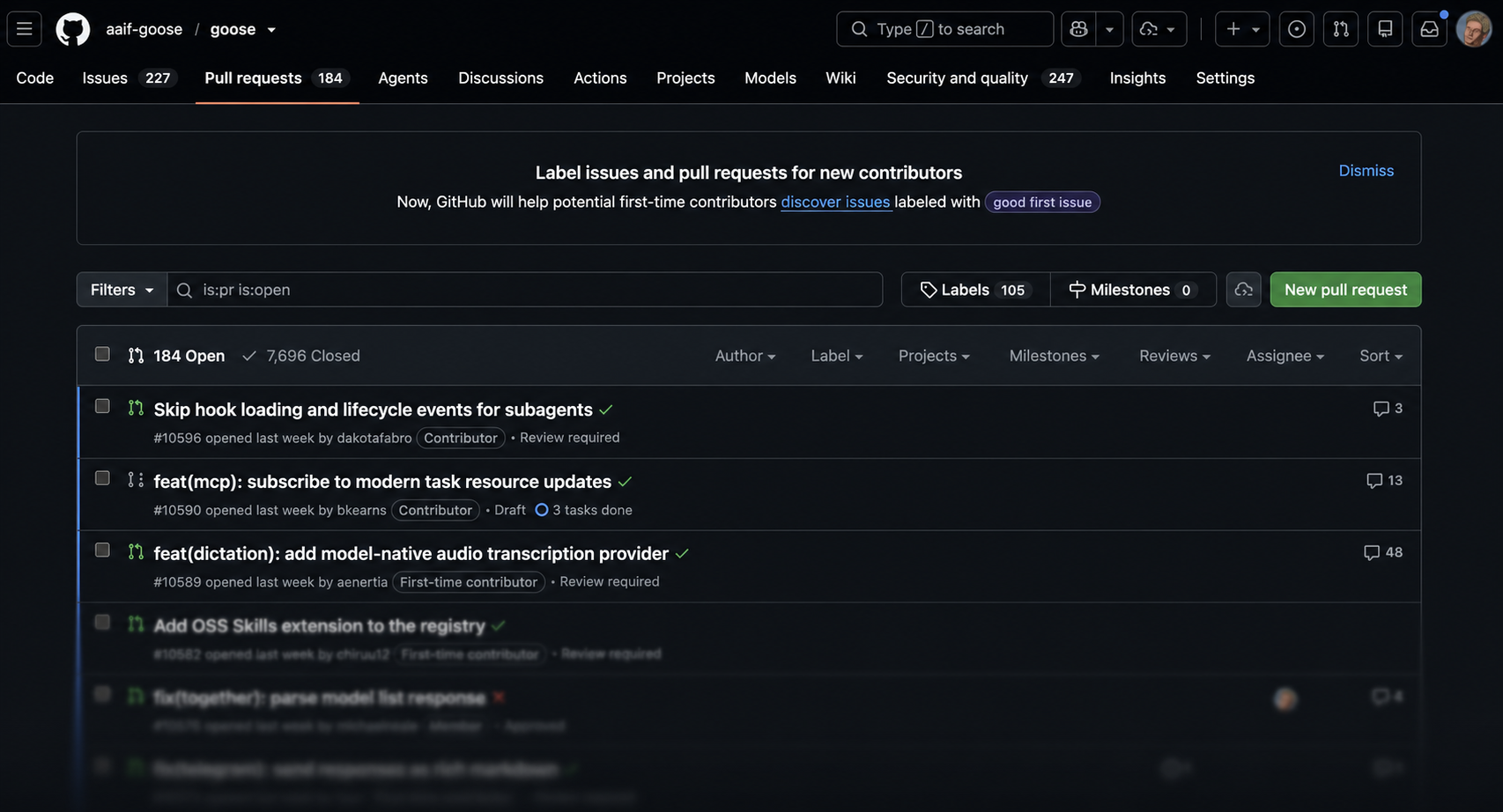
Coding agents have changed all this. The problem is not code quality. Complaints about AI slop are all over the internet, but code written by agents is often better than what you would get from a first-time contributor. The problem is that agents have changed the economics of open source.